
 0
0 0
0
Hadoop技术已经无处不在。不管是好是坏,Hadoop已经成为大数据的代名词。短短几年间,Hadoop从一种边缘技术成为事实上的标准。看来,不仅现在Hadoop是企业大数据的标准,而且在未来,它的地位似乎一时难以动摇。
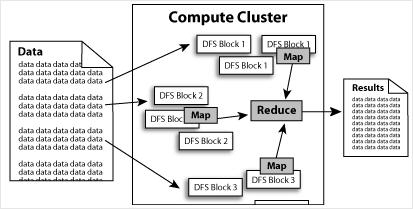
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,Hadoop旗下有很多经典子项目,比如HBase、Hive等,这些都是基于HDFS和MapReduce发展出来的。要想了解Hadoop,就必须知道HDFS和MapReduce是什么。
HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
⒈高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
⒉高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
⒊高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
⒋高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
Hadoop带有用 Java 语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
1、存储文件的时候需要指定存储的路径,这个路径是HDFS的路径。而不是哪个节点的某个目录。比如./hadoop fs -put localfile hdfspat
一般操作的当前路径是/user/hadoop比如执行./hadoop fs -ls .实际上就相当于./hadoop fs -ls /user/hadoop
2、HDFS本身就是一个文件系统,在使用的时候其实不用关心具体的文件是存储在哪个节点上的。如果需要查询可以通过页面来查看,也可以通过API来实现查询。
 粘粘世界 (World of Goo)中文版
70.7M / 中文08-11
粘粘世界 (World of Goo)中文版
70.7M / 中文08-11
 孤胆枪手(重临)v1.0 英文版
21.6M / 英文05-01
孤胆枪手(重临)v1.0 英文版
21.6M / 英文05-01
 GARNET CRADLE Sugary Sparkle
482.1M / 日文10-16
GARNET CRADLE Sugary Sparkle
482.1M / 日文10-16
 nHancer v2.5.7游戏配置工具
1.5M / 中文10-09
nHancer v2.5.7游戏配置工具
1.5M / 中文10-09
 宝库horad(HOARD)
382.8M / 英文11-27
宝库horad(HOARD)
382.8M / 英文11-27
 dota6.72 test版本下载
7.5M / 英文04-21
dota6.72 test版本下载
7.5M / 英文04-21
 星际争霸2DOTA0.9版(Defence of the Ancients0.9)测试
7.7M / 中文04-25
星际争霸2DOTA0.9版(Defence of the Ancients0.9)测试
7.7M / 中文04-25
 星际争霸2DOTA1.0(Defence of the Ancients1.0)测试版
1.7M / 英文04-25
星际争霸2DOTA1.0(Defence of the Ancients1.0)测试版
1.7M / 英文04-25
 星际争霸2DOTA帝国圣地风暴(SotIS)帝国圣地风暴
2.6M / 中文04-26
星际争霸2DOTA帝国圣地风暴(SotIS)帝国圣地风暴
2.6M / 中文04-26
 Dota6.71b ai版6.71b ai地图
7.6M / 中文04-29
Dota6.71b ai版6.71b ai地图
7.6M / 中文04-29

248.9M / 12-08
RTS即时战略
下载
248.9M / 12-08
RTS即时战略
下载
253.4M / 12-08
RPG角色扮演
下载 妻中蜜3全cg存档
游戏工具 / 28KB
下载
1
妻中蜜3全cg存档
游戏工具 / 28KB
下载
1
 csgo空格键连跳脚本绿色免费版
游戏工具 / 564KB
下载
2
csgo空格键连跳脚本绿色免费版
游戏工具 / 564KB
下载
2
 platform tools工具包官方版v36.0.2
编程软件 / 7.3M
下载
3
platform tools工具包官方版v36.0.2
编程软件 / 7.3M
下载
3
 DNF9周年第十套天空时装补丁
游戏工具 / 1.6M
下载
4
DNF9周年第十套天空时装补丁
游戏工具 / 1.6M
下载
4
 易控王文档加密软件v2017官方版绿色免费版
文件处理 / 46M
下载
5
易控王文档加密软件v2017官方版绿色免费版
文件处理 / 46M
下载
5
 vba for wps安装包v7.1官方版
编程软件 / 35.0M
下载
6
vba for wps安装包v7.1官方版
编程软件 / 35.0M
下载
6
 3456wg多选皮肤v10.6官方版
游戏工具 / 2.2M
下载
7
3456wg多选皮肤v10.6官方版
游戏工具 / 2.2M
下载
7
 GTKWave(WAV文件波形察看工具)v3.3.66 官方版
文件处理 / 4.4M
下载
8
GTKWave(WAV文件波形察看工具)v3.3.66 官方版
文件处理 / 4.4M
下载
8
 苹果ios10强制降级工具绕过验证1.0 官方版
文件处理 / 60M
下载
9
苹果ios10强制降级工具绕过验证1.0 官方版
文件处理 / 60M
下载
9
 支付宝AR红包小工具1.0 绿色版
文件处理 / 255KB
下载
10
支付宝AR红包小工具1.0 绿色版
文件处理 / 255KB
下载
10
153M / 06-05
 立即下载
立即下载
444M / 06-05
 立即下载
立即下载
497M / 06-05
 立即下载
立即下载
2.34G / 06-05
 立即下载
立即下载
815.1M / 06-05
 立即下载
立即下载
1.33G / 06-05
 立即下载
立即下载
600M / 06-05
 立即下载
立即下载
18M / 06-04
 立即下载
立即下载
1.35G / 06-04
 立即下载
立即下载
892.3M / 06-04
 立即下载
立即下载
985.7M / 06-08
 立即下载
立即下载
301.0M / 06-08
 立即下载
立即下载
34.60G / 06-08
 立即下载
立即下载
2.63G / 06-08
 立即下载
立即下载
926.0M / 06-08
 立即下载
立即下载
847.0M / 06-08
 立即下载
立即下载
296.2M / 06-05
 立即下载
立即下载
35.0M / 06-05
 立即下载
立即下载
365.2M / 06-05
 立即下载
立即下载
234.2M / 06-05
 立即下载
立即下载
11.2M / 06-05
 立即下载
立即下载 45.5M / 06-05
 立即下载
立即下载 14.1M / 06-05
 立即下载
立即下载 26.2M / 06-05
 立即下载
立即下载 133M / 06-05
 立即下载
立即下载 390.3M / 06-05
 立即下载
立即下载 8M / 06-04
 立即下载
立即下载 156M / 06-04
 立即下载
立即下载 91.7M / 06-04
 立即下载
立即下载 21M / 06-04
 立即下载
立即下载 181.9M / 06-05
 立即下载
立即下载 46M / 06-05
 立即下载
立即下载 88.6M / 06-05
 立即下载
立即下载 29.7M / 06-05
 立即下载
立即下载 870.4M / 06-05
 立即下载
立即下载 44M / 06-05
 立即下载
立即下载 13.7M / 06-05
 立即下载
立即下载 29.30G / 06-04
 立即下载
立即下载 25.34G / 06-04
 立即下载
立即下载 2.73G / 06-04
 立即下载
立即下载 1.05G / 06-05
 立即下载
立即下载 2.49G / 06-01
 立即下载
立即下载 9.84G / 06-01
 立即下载
立即下载 956.1M / 05-28
 立即下载
立即下载 181.5M / 05-28
 立即下载
立即下载 255.9M / 05-28
 立即下载
立即下载 245.1M / 05-28
 立即下载
立即下载 1.07G / 05-28
 立即下载
立即下载 113.2M / 05-28
 立即下载
立即下载 240.0M / 05-28
 立即下载
立即下载 25.7M / 06-05
 立即下载
立即下载 120.5M / 06-05
 立即下载
立即下载 1.10G / 06-05
 立即下载
立即下载 6.09G / 06-04
 立即下载
立即下载 8M / 06-04
 立即下载
立即下载 3.30G / 06-04
 立即下载
立即下载 820.0M / 06-04
 立即下载
立即下载 30.2M / 06-04
 立即下载
立即下载 310.4M / 06-04
 立即下载
立即下载 8M / 06-04
 立即下载
立即下载 231.5M / 06-05
 立即下载
立即下载 79.6M / 06-05
 立即下载
立即下载 17.7M / 06-05
 立即下载
立即下载 499.9M / 06-05
 立即下载
立即下载 160M / 06-04
 立即下载
立即下载 60M / 06-04
 立即下载
立即下载 254.8M / 06-04
 立即下载
立即下载 268M / 06-04
 立即下载
立即下载 232.0M / 06-04
 立即下载
立即下载 1.40G / 12-19
 立即下载
立即下载 35.6M / 06-05
 立即下载
立即下载 4.07G / 06-05
 立即下载
立即下载 222.0M / 06-05
 立即下载
立即下载 13.4M / 01-03
 立即下载
立即下载 293.0M / 09-05
 立即下载
立即下载 1.22G / 07-06
 立即下载
立即下载 20.53G / 07-06
 立即下载
立即下载 229.9M / 07-06
 立即下载
立即下载 3.70G / 07-06
 立即下载
立即下载 904.0M / 07-06
 立即下载
立即下载 









